Agenda
- 背景
- Hotspot 中的 intrinsic method
- 为 BLAS 算子创建 intrinsic
背景 1
什么是 intrinsic method?
- 在编译器领域,用某种编程语言编写的某个函数在转换成机器指令的过程中被编译器特殊处理了,这样的函数称为 intrinsic method。
- 这里的特殊处理并不是就编译优化而言的,通常是用一组预先生成好的指令(或者是 IR)替换目标函数原本的实现。
- 这种替换可以带来收益的主要原因是预先生成好的指令比编译器编译生成的指令更优。
静态编译器中的 intrinsic method
-
Microsoft Visual C/C++ Compiler
__debugbreak()inserts an “int3” instruction for breaking into debugger -
GCC
__builtin_ia32_pause()inserts a “pause” instruction and necessary compiler barriers to prevent the instruction from floating around
JVM 中的 intrinsic mehtod
-
多样性
- 不能假设某个函数在所有 JVM 中都实现了 intrinsic
- Hotspot 中的 intrinsic 可以通过解释器、C1 或 C2 实现
-
兼容性
- intrinsic 版本和字节码版本的函数行为基本一致
- 如果 intrinsic 不能执行,必须可以回退到字节码版本执行
-
可靠性
- 相比于编译器优化,比如循环优化,使用 intrinsic 可能是一个更加可靠的优化办法,因为它影响范围较小,效果更加直接可见
- e.g.
java.lang.System.arraycopy()相较于识别其中的循环然后进行优化,识别这个函数然后直接走 intrinsic 版本更加容易
-
扩展了 Java 语义
- e.g.
sun.misc.Unsafe.compareAndSwapInt()on x86/AMD64 没有 Java 字节码可以表示这个函数的语义 -
所以一般只能用 JNI 调用本地库函数的方法来实现这个方法,但是 JNI 有缺点:
- 不能被 inline
- 调用开销较大
- intrinsify 这个方法后,可以直接使用
cmpxchg这条指令,并且 inline 到 caller 中
- e.g.
Hotspot 中的 intrinsic method1
哪些函数已经被 intrinsify
-
JDK core library 中的某些 API
- 这些 API 的性能已经被优化
- 所以在代码中尽量使用 core library 中的 API
-
特殊的内部函数
- 为了实现特殊的语义
- 从而可以使用 Java 语言实现更多的 JDK core library API
实现 intrinsic
- 在 vmSymbols 中声明 intrinsic method
-
实现 intrinsic method
- Interpreter
- C1
- C2
例子: java.lang.Math.log()
-
Interpreter
-
java.lang.Math.log() (Java / core library)
- (-> through special interpreter method entry)
- “flog” x87 instruction (x86 / AMD64)
-
-
C1 and C2
- inlined into caller as “flog” x87 instruction (x86 / AMD64)
查看哪些函数被 intrinsified
-
-XX:+PrintCompilation -XX:+PrintInlining
- (prepend-XX:+UnlockDiagnosticVMOptionswhen running on product VM)
-
例子
public class Foo { private static Object bar() { return Thread.currentThread(); } public static void main(String[]args) { while (true) { bar(); } } } -
输出
java -XX:+UnlockDiagnosticVMOptions -XX:CompileCommand=’exclude,Foo,main’ -XX:+PrintCompilation2 -XX:+PrintInlining Foo
CompilerOracle: exclude Foo.main50 1 n java.lang.Thread::currentThread(0 bytes) (static)### Excluding compile: static Foo::main50 2 Foo::bar (4 bytes)@ 0 java.lang.Thread::currentThread(0 bytes) (intrinsic)
为 BLAS API 创建 intrinsic
BLAS 简介
-
BLAS(Basic Linear Algebra Subprograms)是一个 API标准,用以规范发布基础线性代数操作的数值库。该程序集最初发布于 1979 年,并用于创建更大的数值程序包(如 LAPACK)。在高性能计算领域,BLAS 被广泛使用。例如,LINPACK 的运算成绩很大程度上取决于 BLAS 中子程序 DGEMM 的表现。为提高性能,许多软硬件厂商都有专门的针对其产品的高性能 BLAS 实现。(维基百科)
-
BLAS 级别
-
Level1:矢量 - 矢量运算
\[y \leftarrow \alpha x + y\] -
Level2:矩阵 - 矢量运算
\[y \leftarrow \alpha Ax + \beta y\] -
Level3:矩阵 - 矩阵运算
\[C \leftarrow \alpha AB + \beta C\]
-
-
实现
-
Netlib BLAS 3
官方实现,使用 Fortran 77 语言编码
-
ACML
AMD 的 BLAS 实现
-
CUDA SDK
NVIDIA CUDA SDK 中包含了 BLAS,可以在显卡上运行
-
GotoBLAS
后藤和茂(Goto)开发的开源 BLAS 实现,目前已经停止开发,被 OpenBLAS 继承
-
OpenBLAS
继承了 GotoBLAS 的实现,主要由中科院软件研究所与计算科学实验室进行开发
-
ESSL
IBM 的 BLAS 实现
-
Intel MKL
Intel 核心数学库
-
GSL
GNU 科学数值库
-
RenderScript IntrinsicBLAS
Android 移动终端高性能 BLAS 实现
-
KML
华为 BLAS 实现,基于 OpenBLAS
-
APL
ARM 公司的 BLAS 实现,有商业版本和免费版本两种
-
在 Hotspot 中 intrinsify BLAS 函数的动机
-
大数据场景中有部分 Spark 程序的热点集中在 BLAS API 中,比如:DDOT、DGEMV、DGEMM 等
- BLAS 既有字节码实现的 Java 库,也有机器指令实现的 native 库
- 接口调用原理如下:
graph LR; id1(com.github.fommil.netlib.BLAS) --> id2(NativeSystemBLAS: 第三方 BLAS); id1 --> id3(Netlib native BLAS: Fortran to native BLAS); id1 --> id4(Netlib F2j BLAS: Fortran to Java bytecode BLAS); id2 --> id5(native_system-java.jar); id5 -->|JNI| id6(netlib-native_system.so); id6 --> id7(libopenblas.so); id7 -->|link| id8(OpenBLAS/KML); - Netlib BLAS 的算法实现没有经过太多优化,存在从算法层面提升性能的空间
- 即使使用了第三方的 BLAS 库,算法层面得到优化,但还是存在 JNI 的开销,在某些数据模型下影响较大
如何实现 BLAS API ?
目前针对 Aarch64 平台的 BLAS 库实现有:
- APL:ARM 公司出品的商业软件
- Netlib BLAS:没有做过深度优化,性能平平
- OpenBLAS:做了大量算法和体系结构方面的优化,性能优秀 4
- 我们自己实现的 BLAS API:性能表现明显没有好于 OpenBLAS,且未经过严格测试和长期使用,可靠性存疑
通过分析 OpenBLAS 源码,并依据相关论文 56 中的性能比对结果可以看出使用 OpenBLAS 的实现似乎是一个不错的选择。
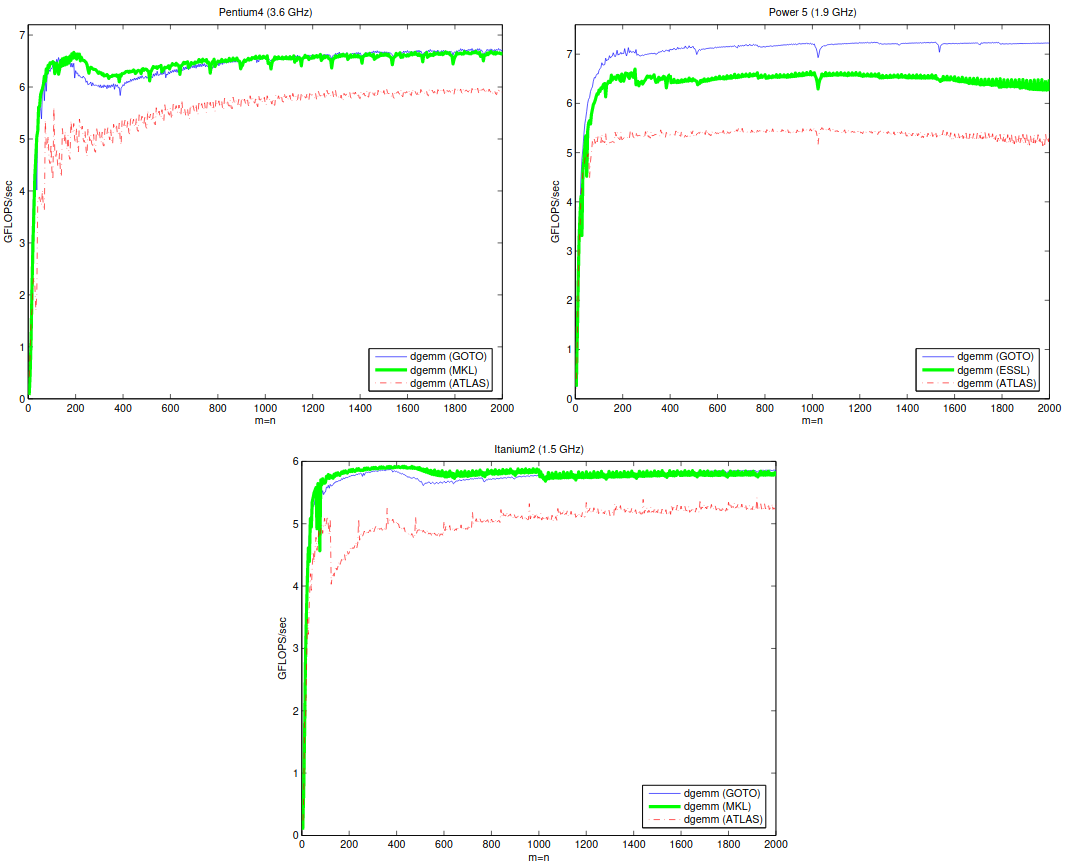
综上,我们选择 OpenBLAS 作为 intrinsice 的实现来源。
实现 BLAS intrinsic method
在开始实现 intrinsic method 前,我们似乎还有几个问题没有解决。
为什么 JVM 没有 intrinsify 第三方的 API ?
- 第三方 API 实现不属于 JDK 软件范畴
- 外部 API 不受 JDK 控制,其接口可能发生变化,而 JDK 不会感知
- 外部 API 的编码实现可能受算法演进或平台演进而变化,而 JDK 不会感知
- 如果 intrinsic 函数实现参考库实现,存在开源法律风险
Intrinsify BLAS 库中的 API 为什么可以 ?
- BLAS 已经发展了 40 多年,目前接口非常稳定,各种 BLAS 库实现遵循同一套 API 标准
-
Intrinsic 中只包含调用 API 的逻辑,然后通过动态库加载调用 API 实现,如下图所示:
graph LR; id1(com.github.fommil.netlib.BLAS.dgemm) --> id2(Interpreter); id1 --> id3(C1); id1 --> id4(C2); id2 --> id5(Stub); id3 --> id5(Stub); id4 --> id5(Stub); id5 -.-> id6(libopenblas.so); id6 -->|link| id7(BLAS implementation); - OpenBLAS 采用 BSD 开源 license,可以放心使用
- 这种 intrinsic 实现方式没有改变 JDK 的软件定位
DGEMM 函数简介
这里以 DGEMM 函数为例进行说明。
- 函数功能 7
DGEMM performs one of the matrix-matrix operations
C := alphaop( A )op( B ) + beta*C,
where op( X ) is one of
op( X ) = X or op( X ) = X**T,
alpha and beta are scalars, and A, B and C are matrices, with op( A ) an m by k matrix, op( B ) a k by n matrix and C an m by n matrix.
-
函数实现
C2 intrinsic 实现步骤
在 C2 中添加 intrinsic 并不是一个简单的过程,所以下面每一步完成后最好编译一下,以节省调试时间。9
添加选项开关
目前 Hotshot 中的 intrinsic 一般都有自己对应的开关,另外为了方便使用和调试,有必要加入一个专门的选项来控制 BLAS intrinsic 的开关。代码位于 hotspot/src/share/vm/runtime/globals.hpp 中:
#define RUNTIME_FLAGS(develop, develop_pd, product, product_pd, diagnostic, experimental, notproduct, manageable, product_rw, lp64_product) \
// ...
experimental(bool, UseF2jBLASIntrinsics, false, "use intrinsics for org.netlib.blas.xxx on aarch64") \
// ...
注意,由于选项使用了 experimental 类型,所以需要额外搭配 UnlockExperimentalVMOptions 才能生效。另外我们目前只做了 aarch64 平台的 intrinsic,所以其他平台应该关闭此选项,以免发生错误,修改 hotspot/src/cpu/xxx/vm/vm_version_xxx.cpp 如下:
void VM_Version::initialize() {
// ...
if (UseF2jBLASIntrinsics) {
// ...
FLAG_SET_DEFAULT(UseF2jBLASIntrinsics, false);
}
// ...
}
准备 DGEMM 的函数实现
由于前面说过 DGEMM 的实现来自 OpenBLAS,所以我们只要在 JVM 启动时动态加载 OpenBLAS 库就能获取对应的函数入口。下面给出 hotspot/src/cpu/aarch64/vm/stubGenerator_aarch64.cpp 中加载函数的实现和调用:
address load_BLAS_library() {
const char library_name[] = "openblas";
// ...
char buf[JVM_MAXPATHLEN];
os::jvm_path(buf, sizeof(buf));
// ...
strcpy(&buf[jvm_offset], library_name);
strcpy(&buf[jvm_offset], os::dll_file_extension());
library = (address)os::dll_load(buf, ebuf, sizeof(ebuf));
// ...
return library;
}
// ...
void generate_initial() {
// ...
if (UseF2jBLASIntrinsics) {
StubRoutines::_BLAS_library = load_BLAS_library();
// ...
}
}
请注意,这里将动态库加载的操作放在了 generate_initial 而不是 generate_all 中,因为在初始化 Hotspot 时 generate_initial 先于 interpreter_init,将动态库加载操作放在 generate_initial 中可以保证 interpreter 也能正确获取动态库。
定义 intrinsic
首先,我们来看一下需要 intrinsify 的函数 dgemm,其定义位于 Dgemm.class 中:
package org.netlib.blas;
import org.netlib.err.Xerbla;
public final class Dgemm {
public static void dgemm(String transa, String transb, int m, int n, int k, double alpha, double[] a, int a_off, int lda, double[] b, int b_off, int ldb, double beta, double[] c, int c_off, int ldc) {
// ...
}
}
然后,让我们来到文件 hotspot/src/share/vm/classfile/vmSymbols.hpp 中,这里定义了 Hotspot 里所有的 intrinsic。我们只需要添加如下定义,之后就可以在 Hotspot 内部以_f2jblas_dgemm 为 ID 识别 dgemm 了:
do_class(org_netlib_blas_dgemm, "org/netlib/blas/Dgemm") \
do_name(dgemm_name, "dgemm") \
do_signature(dgemm_signature, "(Ljava/lang/String;Ljava/lang/String;IIID[DII[DIID[DII)V") \
do_intrinsic(_f2jblas_dgemm, org_netlib_blas_dgemm, dgemm_name, dgemm_signature, F_S) \
为 intrinsic 生成 Stub
根据上面的描述,我们只需要生成调用动态库中 dgemm 函数的指令就可以实现该 intrinsic。相关代码位于 hotspot/src/cpu/aarch64/vm/stubGenerator_aarch64.cpp 中:
address generate_dgemmF2jBLAS(address library) {
// ...
// 根据之前加载的动态库搜索 dgemm 函数入口
address fn = get_BLAS_func_entry(library. "dgemm_");
if (fn == NULL) return NULL;
address start = __ pc();
// 父函数参数获取
// ...
// 子函数参数准备
// ...
// 子函数调用
__ blr(fn);
// ...
return start;
}
这里的子函数即是加载动态库中的函数接口 dgemm_,其参数都是指针类型,所以在参数准备阶段需要做参数转换的工作,他的定义位于 OpenBLAS/interface/gemm.c 中:
void NAME(char *TRANSA, char *TRANSB,
blasint *M, blasint *N, blasint *K,
FLOAT *alpha,
IFLOAT *a, blasint *ldA,
IFLOAT *b, blasint *ldB,
FLOAT *beta,
FLOAT *c, blasint *ldC) {
// ...
}
虽然获取上层调用函数参数和准备调用子函数参数的实现并不是唯一的,但是无论哪种实现都要符合 《Procedure Call Standard for the Arm® 64-bit Architecture》。
现在我们需要在 hotspot/src/share/vm/runtime/stubRoutines.hpp 中添加一个变量来保存上面这个生成方法的入口地址以及返回这个变量的方法:
static address _dgemmF2jBLAS;
static address dgemmF2jBLAS() { return _dgemmF2jBLAS; }
最后还是在 hotspot/src/cpu/aarch64/vm/stubGenerator_aarch64.cpp 的 generate_initial 中调用 generate_dgemmF2jBLAS 完成代码生成:
void generate_initial() {
// ...
if (UseF2jBLASIntrinsics) {
StubRoutines::_BLAS_library = load_BLAS_library();
StubRoutines::_dgemmF2jBLAS = gnerate_dgemmF2jBLAS(StubRoutines::_BLAS_library);
// ...
}
}
添加创建 intrinsic 描述符的函数
为了能在 Ideal Graph 中正确地创建 Call 节点——这个 Call 节点代表了对上述生成代码的调用,需要一个描述 Call 节点所表示函数的入参信息和返回值信息的数据结构,这个数据结构会使用 hotspot/src/share/vm/opto/runtime.cpp 中的对应函数生成:
const TypeFunc* OptoRuntime::dgemmF2jBLAS_Type() {
// double 类型参数占两个
int num_args = 15;
int argcnt = num_args;
const Type** fields = TypeTuple::fields(argcnt);
int argp = TypeFunc::Parms;
// char[]
fields[argp++] = TypeAryPtr::CHARS;
// ...
// int
fields[argp++] = TypeInt::INT;
// ...
// double 占两个位置
fields[argp++] = Type::DOUBLE;
fields[argp++] = Type::HALF;
// ...
// double[]
fields[argp++] = TypeAryPtr::DOUBLES;
// ...
// return value
// void
fields = TypeTupe::fields(1);
fields[TypeFunc::Parms + 0] = NULL;
// ...
}
编译期识别并 inline 目标函数
有了上述准备之后,就可以在 C2 生成 IR 的过程中将我们的 intrinsic method inline 到父方法中。具体由 hotspot/src/share/vm/opto/library_call.cpp 中的 LibraryCallKit::inline_dgemmF2jBLAS 实现:
bool LibraryCallKit::inline_dgemmF2jBLAS() {
// ...
// 判断 intrinsic 指令是否已经生成,如果没有,则走正常字节码编译流程
address stubAddr = StubRoutines::dgemmF2jBLAS();
if (stubAddr == NULL) return false;
// 获取参数,这里的参数个数和类型和 org/netlib/blas/Dgemm/dgemm 一致
// 由于我们的目标函数 dgemm 是 static 类型,所以第一个参数直接就是入参,而不是类对象引用
Node* transa = argument(0);
// ...
// double 类型占据两个 slot
Node* alpha = round_double_node(argument(5));
Node* a = argument(7);
// ...
// 计算 String 类中 char 数组的起始地址
Node* transa_value = load_String_value(NULL, transa);
Node* transa_offset = load_String_offset(NULL, transa);
Node* transa_start = array_element_address(transa_value, transa_offset, T_CHAR);
// ...
// 计算 double 数组的起始地址
const Type* a_type = a->Value(&_gvn);
const TypeAryPtr* a_base_type = a_type->isa_aryptr();
ciKlass* a_klass = a_base_type->klass();
BasicType a_elem_type = a_klass->as_array_klass()->element_type()->basic_type();
Node* a_start = array_element_address(a, a_offset, a_elem_type);
// ...
// 生成 call 节点
make_runtime_call(RC_LEAF, OptoRuntime::dgemmF2jBLAS_Type(),
stubAddr, stubName, TypePtr::BOTTOM,
transa_start, transb_start, m, n, k, alpha, top(),
a_start, lda, b_start, ldb, beta, top(), c_start, ldc);
// ...
return true;
}
这里需要注意的是,由于 dgemm 的参数个数已经超出了 make_runtime_call 的上限,所以需要修改 hotspot/src/share/vm/opto/graphKit.cpp 中 GraphKit::make_runtime_call 的定义。
最后,我们需要告知 Hotspot 对 dgemm 函数执行 inline_dgemmF2jBLAS 方法,在这之前我们还需要解除 Hotspot 对外部类 intrinsic 的限制,修改 hotspot/src/share/vm/oops/method.cpp 如下:
Method::klass_id_for_intrinsics(Klass* holder) {
InstanceKlass* ik = InstanceKlass::cast(holder);
if ((ik->class_loader() != NULL) &&
!SystemDictionary::is_ext_class_loader(ik->class_loader())) {
if (!EnableIntrinsicExternal) {
return vmSymbols::NO_SID;
}
}
}
我们通过在 hotspot/src/share/vm/opto/library_call.cpp 中添加 case 处理识别 dgemm,并调用 inline 函数:
CallGenerator* Compile::make_vm_intrinsic(ciMethod* m, bool is_virtual) {
// ...
case vmIntrinsics::_f2jblas_dgemm:
if (!UseF2jBLASIntrinsics) return NULL;
break;
// ...
}
bool LibraryCallKit::try_to_inline(int predicate) {
// ...
case vmIntrinsics::_f2jblas_dgemm:
return inline_dgemmF2jBLAS();
// ...
}
C1 实现步骤
在 C1 中添加 intrinsic 的流程和 C2 略有不同,主要原因在于两者使用了不同的 IR,但仍然可以复用已经生成的 intrinsic 指令。
在 LIR 中调用 intrinsic
C1 会先将字节码转换成 HIR,优化后再转化成 LIR,最后根据每条 LIR 指令转化成机器指令,所以在 LIR 生成的过程中会识别特定的 HIR——这个 HIR 表示目标函数调用,并生成可以调用 intrinsic 指令的 LIR。生成 LIR 的函数位于 hotspot/src/cpu/aarch64/vm/c1_LIRGenerator_aarch64.cpp 中:
void LIRGenerator::do_f2jblas_dgemm(Intrinsic* x) {
// 加载参数
LIRItem ta(x->argument_at(0), this);
// ...
LIRItem alpha(x->argument_at(5), this);
// ...
// 获取 String 对象中 char 数组的起始地址
LIR_Opr ta_base = ta.result;
LIR_Opr ta_value = new_register(T_ARRAY);
ta_value = load_String_value(ta_base);
LIR_Opr ta_value = new_register(T_INT);
ta_offset = load_String_offset(ta_base);
LIR_Addreess* addr_ta = emit_array_address(ta_value, ta_offset, T_CHAR, false);
// ...
// 将地址放入寄存器
// 这里使用的所有指令都是 LIR 指令
LIR_Opr tmp = new_pointer_register();
LIR_Opr ta_addr = new_register(T_ADDRESS);
__ leal(LIR_OprFac::adddress(addr_ta), tmp);
__ move(tmp, ta_addr);
// ...
// 生成调用 intrinsic 指令的 LIR
// 定义和 intrinsic 对应的函数签名,用来在寄存器分配阶段将入参正确地分配到寄存器
BasicTypeList signature(13);
signature.append(T_ADDRESS);
signature.append(T_ADDRESS);
signature.append(T_INT);
// ...
LIR_OprList* args = new LIR_OprList();
args->append(ta_addr);
// ...
call_runtime(&signature, args, StubRoutines::dgemmF2jBLAS(), voidType, NULL);
set_no_result(x);
}
当 LIR 层发现有 intrinsic 的 HIR 时,调用上面的函数生成对应的 LIR 指令,代码位于和上面函数同一文件中:
void LIRGenerator::do_intrinsic(Intrinsic* x) {
// ...
case vmIntrinsic::_f2jblas_dgemm:
do_f2jblas_dgemm(x);
break;
// ...
}
和 C2 不同的是,C1 中没有现成的 load_String_value 和 load_String_offset 可以使用,需要自己实现,实现逻辑和 C2 相同。此外,还需要注意的是,由于这里使用了 T_ADDRESS 类型,在寄存器分配中可能会触发 JDK-8236179 描述的 failure,此问题已在 aarch64 OpenJDK8u292 中修复 10。
在 HIR 层中识别 intrinsic
通过 intrinsic ID,识别目标函数,并生成相应的 HIR intrinsic 表示,代码位于 hotspot/src/share/vm/c1/c1_GraphBuilder.cpp 中:
bool GraphBuilder::try_inline_intrinsics(ciMethod* callee) {
// ...
case vmIntrinsics::_f2jblas_dgemm:
if (!UseF2jBLASIntrinsics || (StubRoutines::dgemmF2jBLAS() == NULL) {
return false;
}
cantrap = false;
preserves_state = true;
break;
// ...
}
但是仅仅这样 C1 并不会生成 intrinsic 指令,原因在于 HIR 会将 use 为 0 的指令优化掉,优化前的 HIR 如下:
B1 [0, 0] -> B0 sux: B0
empty stack
inlining depth 0
__bci__use__tid____instr____________________________________
. 0 0 21 std entry B0
B0 (SV) [0, 29] pred: B1
empty stack
inlining depth 0
__bci__use__tid____instr____________________________________
11 0 i15 0
26 0 v18 Dgemm.f2jblas_dgemm(a2, a3, i4, i5, i6, d7, a8, i15, i9, a10, i15, i11, d12, a13, i15, i14)
. 29 0 v19 return
优化后的 HIR:
B1 [0, 0] -> B0 sux: B0
empty stack
inlining depth 0
__bci__use__tid____instr____________________________________
. 0 0 5 std entry B0
B0 (SV) [0, 4] dom B1 pred: B1
empty stack
inlining depth 0
__bci__use__tid____instr____________________________________
. 29 0 v19 return
为了使 C1 正确生成 intrinsic,可以将目标函数设置成 pinned。相关代码位于 hotspot/src/share/vm/classfile/vmSymbols.cpp:
bool vmIntrinsics::should_be_pinned(vmIntrinsics::ID id) {
// ...
case vmIntrinsics::_f2jblas_dgemm:
return true;
// ...
}
Interpreter 实现步骤
相比之下,在解释器中实现 intrinsic 调用比较直接,因为少了 IR 转换,所以直接从字节码层面获取参数,并直接使用机器指令调用 intrinsic。
生成 intrinsic 调用指令
解释器中获取入参的方法比较直接,就是通过操作数栈中的偏移位置,加载参数。然后准备好调用 intrinsic 的参数,最后调用即可。其中的细节需要特别注意,比如宏汇编的使用要准确,调用栈的维护要正确,代码位于 hotspot/src/cpu/aarch64/vm/templateInterpreter_aarch64.cpp 中:
address InterpreterGenerator::generate_F2jBLAS_dgemm_entry() {
if (!UseF2jBLASIntrinsics || (StubRoutines::dgemmF2jBLAS() == NULL)) return NULL;
address entry = __ pc();
// 获取参数 ta,并根据调用 intrinsic 的入参顺序手工分配寄存器和压栈(如果需要的话)
// 这里的 esp 是 Java 的栈寄存器
// load_String_value\load_String_offset\emit_array_address 这几个辅助函数需要自己实现
const Register ta = c_rarg0;
__ ldr(ta, Address(esp, 17 * worSize);
load_String_value(ta, tmp1);
load_String_offset(ta, tmp2);
emit_array_address(tmp1, tmp2, ta, T_CHAR);
// ...
// 调用 intrinsic
address fn = CAST_FROM_FN_PTR(address, StubRoutines::dgemmF2jBLAS());
__ mov(tmp1, fn);
__ blr(tmp1);
// ...
// 返回上层栈帧
__ br(lr);
return entry;
}
该函数在解释器初始化时被调用,代码如下:
address AbstractInterpreterGenerator::generate_method_entry() {
// ...
case Interpreter::org_netlib_blas_Dgemm_dgemm
: entry_point = ((InterpreterGenerator*)this)->generate_F2jBLAS_dgemm_entry(); break;
// ...
}
需要注意的是,由于这里需要获取 String 类的 offset 信息,而目前 JDK8 的解释器初始化位于 String 类 offset 信息初始化前,所以会有问题。对此, JDK 高版本中已经有了解决方案(JDK-8243996)。
注册 intrinsic entry
在模板解释器 hotspot/src/share/vm/interpreter/templateInterpreter.cpp 中为 intrinsic 注册上面生成的入口地址:
void TemplateInterpreterGenerator::generate_all() {
// ...
if (UseF2jBLASIntrinsics) {
method_entry(org_netlib_blas_Dgemm_dgemm)
}
// ...
}
最后在解释执行中识别 intrinsic ID,从注册表中获取入口地址,完成调用,代码位于 hotspot/src/share/vm/interpreter/interpreter.cpp:
AbstractInterpreter::MethodKind AbstractInterpreter::method_kind(methodHandle m) {
// ...
if (UseF2jBLASIntrinsics) {
switch (m->intrinsic_id()) {
case vmIntrinsics::_f2jblas_dgemm: return org_netlib_blas_Dgemm_dgemm;
}
}
// ...
}
正确性验证
-
从结果角度出发,使用 intrinsic 和未使用 intrinsic 的计算结果应该基本一致
- 因为如果计算对象是浮点数,精度会有明显区别
- 从调试角度出发,由于 C2/C1/Interpreter 每种实现都有 generator,只要记录指令生成入口地址,就能 GDB 调试,验证 intrinsic 执行正确性
-
另外可以利用 Hotspot 选项,打印生成的 Stub 指令来判断正确性:
-
-XX:+PrintStubCodeStubRoutines::f2jblas_dgemm [0x0000ffff74075b80, 0x0000ffff74075bec[ (108 bytes) ;; Entry: 0x0000ffff74075b80: sub sp, sp, #0x60 0x0000ffff74075b84: stp x29, x30, [sp, #48] 0x0000ffff74075b88: add x29, sp, #0x30 ;; 0xFFFF81BA40A8 0x0000ffff74075b8c: mov x8, #0x40a8 // #16552 0x0000ffff74075b90: movk x8, #0x81ba, lsl #16 0x0000ffff74075b94: movk x8, #0xffff, lsl #32 0x0000ffff74075b98: ldr x9, [x29, #56] 0x0000ffff74075b9c: stp w3, w2, [x29, #40] 0x0000ffff74075ba0: add x2, x29, #0x10 0x0000ffff74075ba4: stp w6, w4, [x29, #32] 0x0000ffff74075ba8: add x3, x29, #0x40 0x0000ffff74075bac: stp x2, x9, [sp, #16] 0x0000ffff74075bb0: add x2, x29, #0x30 0x0000ffff74075bb4: str x7, [sp] 0x0000ffff74075bb8: mov x6, x5 0x0000ffff74075bbc: str x3, [sp, #32] 0x0000ffff74075bc0: add x5, x29, #0x18 0x0000ffff74075bc4: str x2, [sp, #8] 0x0000ffff74075bc8: add x4, x29, #0x24 0x0000ffff74075bcc: stp d1, d0, [x29, #16] 0x0000ffff74075bd0: add x7, x29, #0x20 0x0000ffff74075bd4: add x3, x29, #0x28 0x0000ffff74075bd8: add x2, x29, #0x2c 0x0000ffff74075bdc: blr x8 0x0000ffff74075be0: ldp x29, x30, [sp, #48] 0x0000ffff74075be4: add sp, sp, #0x60 0x0000ffff74075be8: ret
-
性能验证
推荐使用 JMH 对 intrinsic 方法进行性能测试。测试对象可以设为三个:字节码 C2 编译版本、JNI 调用本地库版本、intrinsic 版本。可分别测试低维矩阵运算和高维矩阵运算的性能表现。
命令如下:
java -jar target/xxx.jar -wi <warm times: 10> -i <iterater times: 10> -f <fork times: 1> -jvm <test jvm bin path> -rf <output file type: json> -rff <output file name> Dgemm
低维结果如下:
| Benchmark | (p) | (transa) | (transb) | Mode | Cnt | Score | Error Units |
|---|---|---|---|---|---|---|---|
| Dgemm.BLAS_dgemm_f2j | 7 | N | N | thrpt | 10 | 1316400.761 | ±3432.259 ops/s |
| Dgemm.BLAS_dgemm_f2j | 8 | N | N | thrpt | 10 | 965791.524 | ±1516.582 ops/s |
| Dgemm.BLAS_dgemm_f2j | 9 | N | N | thrpt | 10 | 860861.364 | ±2304.345 ops/s |
| Dgemm.BLAS_dgemm_f2j_intrinsic | 7 | N | N | thrpt | 10 | 1390266.322 | ±2943.701 ops/s |
| Dgemm.BLAS_dgemm_f2j_intrinsic | 8 | N | N | thrpt | 10 | 1424826.639 | ±1992.931 ops/s |
| Dgemm.BLAS_dgemm_f2j_intrinsic | 9 | N | N | thrpt | 10 | 1225997.326 | ±2663.439 ops/s |
| Dgemm.BLAS_dgemm_open | 7 | N | N | thrpt | 10 | 869726.939 | ±4293.571 ops/s |
| Dgemm.BLAS_dgemm_open | 8 | N | N | thrpt | 10 | 894927.360 | ±9968.635 ops/s |
| Dgemm.BLAS_dgemm_open | 9 | N | N | thrpt | 10 | 796290.455 | ±4005.004 ops/s |
中高维结果如下:
| Benchmark | (p) | (transa) | (transb) | Mode | Cnt | Score | Error Units | |
|---|---|---|---|---|---|---|---|---|
| Dgemm.BLAS_dgemm_f2j | 70 | N | N | thrpt | 10 | 2969.096 | ± 2.639 | ops/s |
| Dgemm.BLAS_dgemm_f2j | 80 | N | N | thrpt | 10 | 2004.466 | ± 4.520 | ops/s |
| Dgemm.BLAS_dgemm_f2j | 90 | N | N | thrpt | 10 | 1412.052 | ± 5.198 | ops/s |
| Dgemm.BLAS_dgemm_f2j_intrinsic | 70 | N | N | thrpt | 10 | 12184.291 | ± 382.105 | ops/s |
| Dgemm.BLAS_dgemm_f2j_intrinsic | 80 | N | N | thrpt | 10 | 11713.354 | ± 299.428 | ops/s |
| Dgemm.BLAS_dgemm_f2j_intrinsic | 90 | N | N | thrpt | 10 | 10560.393 | ± 317.499 | ops/s |
| Dgemm.BLAS_dgemm_open | 70 | N | N | thrpt | 10 | 12549.708 | ± 310.946 | ops/s |
| Dgemm.BLAS_dgemm_open | 80 | N | N | thrpt | 10 | 11449.780 | ± 177.613 | ops/s |
| Dgemm.BLAS_dgemm_open | 90 | N | N | thrpt | 10 | 10306.190 | ± 150.359 | ops/s |
参考
{kind=link}
文档信息
- 本文作者:Zhuojun Miao
- 本文链接:https://miaozhuojun.github.io/2021/03/26/Hotspot-intrinsice/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)