背景
Java 语言由于其高效和安全的开发特性和平台无关性被众多开发者广泛使用。但这并不意味着 Java 语言是万能的,在某些情况下它也需要借助其他语言(这里主要指 C/C++/assembly)来实现特定功能,比如:
- 为了避免重复的代码开发,需要利用本地已有的函数库。
- 为了提高代码执行效率或使用硬件特性,比如在 HPC 和大数据等需要大量科学计算的场景中,需要使用更加底层的语言来满足性能要求。
- 为了满足某些不愿意使用 Java 方法的需求,比如 Java core library 实现中的跨 package 的方法调用或者想避免 Java 的安全检查,那么就需要使用本地库来实现。
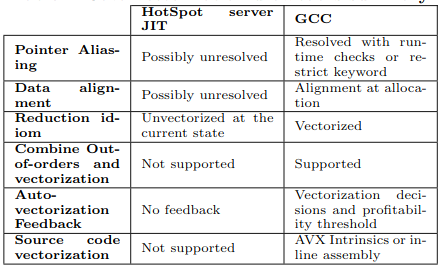
这里需要特别指出的是,Java 运行时编译器 JIT 的自动向量化能力较弱,所以在需要大量向量矩阵运算的高性能计算场景就需要借助 GCC/LLVM 等静态编译器编译优化能力。JIT 和 GCC 在向量化能力对比如下:
目前 Java 语言调用其他语言的方法主要是通过 JNI。JNI 是一个 Java 语言调用本地函数的标准接口,他的优点是兼容性强,可以和各种 JVM 实现交互,对 JVM 运行时的影响也较小。但是正是因为 JNI 的设计原则首先考虑了和 JVM 实现的解耦,导致其性能较差。具体来说,使用 JNI 调用本地库函数有如下几个缺点:
- 每次调用都需要两次 call 跳转,其中第一次是从 JVM 跳转到 JNI wrapper,第二次再从 JNI wrapper 跳转到本地目标函数。这里的第一次跳转其实是可以消除的,也就是说直接从 JVM 跳转到目标函数应该更加合理。
- 本地函数的参数需要通过 JNI wrapper 提供,而 JNI wrapper 是通过运行时回调 JNI API 向 JVM 获取,如果参数包含数组,则可能存在数组拷贝。这里增加了每次调用的回调开销和可能发生的数组拷贝开销。
- JNI wrapper 是用户用 C/C++ 按照 JNI 规范编写的,无法被 JIT 优化,主要是无法被 inline,而 JIT 的许多编译优化都是基于 inline 的,所以这部分性能也不会太好。
- 使用上比较繁琐,用户首先要自己编写 JNI wrapper,然后链接目标库,生成一个 JNI 动态库,最后在 Java 层调用这个代表 JNI wrapper 的 native 方法。开发者需要来回在 C/C++ 和 Java 间切换,不能在 Java 层完成整个调用过程的开发。
优化
从之前在 JVM 中添加 intrinsic 的方案 中,我们似乎可以找到一些灵感。
首先,虽然目前进入 intrinsic 的方式还是通过 call 跳转,但是这部分是可以优化的,如果我们使用 IR 来实现 intrinsic,JIT 就可以对其做 inline,这样就可以减少一次 call 跳转,使 JVM 直接跳转到 native function 执行,并且 inline 后 JIT 还可以继续对 intrinsic 做优化。
其次,由于我们在 intrinsic 中实现了参数从 Java convension 转成 C convension,所以不存在回调的开销。另外,由于在 intrinsic 代码执行时 JVM 不会做 GC(intrinsic 实现中没有添加任何 safepoint),所以参数的传递可以安全地使用引用,消除了可能的数组拷贝开销。
最后,我们还可以提供一套 Java 层 API,用来加载本地动态库,获取 native function 函数句柄,然后以 native function 的函数签名作为输入,自动生成对应的 intrinsic,最后通过 API 调用 native function。整个调用过程都在 Java 层完成,不需要进行跨语言开发。
Call Stub
上面提到的 intrinsic 其实就是 JIT 内部的一个 code stub(一个 IR subgraph),这个 stub 的主要任务是将 Java calling convention 转化为 native calling convention(比如 C calling convention)。由于他是根据 native function 的函数签名自动生成的,如果 native function 的参数是不可变的,那么这个 stub 生成一次就不会再变了,所以可以进一步 inline 这个 stub 的 IR graph 到整个 Java 程序的 IR graph,如果参数是可变的,那么还是需要每次都重新生成 stub,不过这种情况比较罕见。
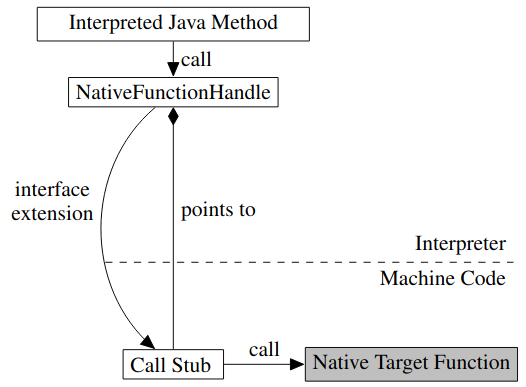
从解释器调用 native function
从解释器调用 native function 需要两次跳转,首先从解释器跳转到 call stub,然后再从 call stub 跳转的 native function。下图展示了这个调用过程:
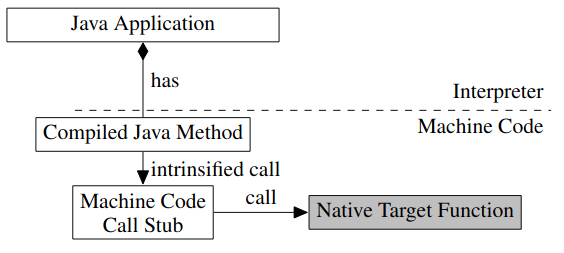
从 JIT 调用 native function
从 JIT 调用 native function 一般只需要跳转一次。开始时,从 compiled code 跳转到 call stub,然后 call stub 再跳转到 native function,如下图所示:
但是如果 native function 的参数是固定的,那么 call stub 也就是固定的,对于编译期不会发生变化的代码,JIT 会试图 inline,所以最终只需要跳转一次就可以调用 native function,效果如下:
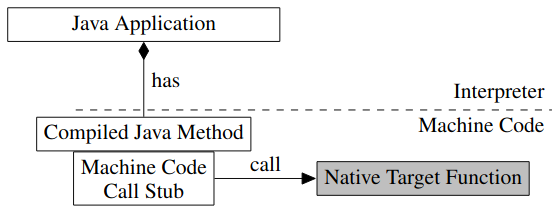
效果
下面给出一个例子来说明使用方法,首先我们先定义一个 C 方法,也就是我们需要调用的 native function。
double floor(double value);
然后使用 Java API 加载动态库,获取方法句柄,同时生成 call stub:
NativeFunctionInterface ffi = XXX.getRequiredCapability(NativeFunctionInterface.class);
NativeLibraryHandle libraryHandle = ffi.getLibraryHandle("libMyMath.so");
NativeFunctionHandle functionHandle = ffi.getFunctionHandle(libraryHandle, "floor",double.class, double.class);
最后通过 NativeFunctionHandle 调用方法 floor。
Object[] arg = new Object[1];arg[0] = new Double(1.5);
double result = Double.longBitsToDouble(functionHandle.call(arg));
取得的性能收益和之前 intrinsic 实现基本一致,都较 JNI 有明显提升。
参考
- An Efficient Native Function Interface for Java
- Performance comparison between Java and JNI for optimalimplementation of computational micro-kernels
- JNI 的作用与工作原理
- Java Native Interface Overview
- Why JNI is slow?
- Bits of Advice for the VM Writer, by Cliff Click @ Curry On 2015
- Understand the overhead of JNI
- Inlining Java Native Calls At Runtime
- Best practices for using the Java Native Interface
- The overhead of native calls in Java
文档信息
- 本文作者:Zhuojun Miao
- 本文链接:https://miaozhuojun.github.io/2021/05/25/a-faster-method-for-Java-call-native-function/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)